[Mysql, Querydsl] 커버링 인덱스와 쿼리 추출을 통한 조회 성능 개선 (트래픽 부하 테스트)
커버링 인덱스 좀 빠르네?
1. 목표 설정
이전 글 에서, 데이터가 2000만 건 이상이 들어있는 개발 서버에서 ‘인기순 전체 게시글 목록 조회’ 기능의 성능을 반정규화를 통해 8초 -> 0.27초로 개선한 바 있다.
물론 0.27초로도 충분하다고 생각할 수 있었다. 하지만 이전 글에서 진행한 트래픽 부하 테스트를 통해 느낀 바로는, 트래픽이 많아지면 많아질수록 성능은 더 떨어지게 된다는 것이다. 그래서 여기서 만족하지 않고 0.1초 이내로 성능을 더 개선시키기로 결정했다.
이전 글에서 반정규화로 성능을 개선한 후부터 발생하고 있는 쿼리를 다시 보자.
select
distinct p1_0.id,
p1_0.created_at,
p1_0.is_hidden,
p1_0.content,
p1_0.title,
p1_0.deadline,
p1_0.updated_at,
p1_0.vote_count,
p1_0.member_id,
w1_0.id,
w1_0.alarm_checked_at,
w1_0.birth_year,
w1_0.created_at,
w1_0.gender,
w1_0.nickname,
w1_0.roles,
w1_0.social_id,
w1_0.social_type,
w1_0.updated_at
from
post p1_0
join
member w1_0
on w1_0.id=p1_0.member_id
left join
post_category p2_0
on p1_0.id=p2_0.post_id
where
p2_0.category_id=1
and p1_0.deadline>'2023-11-04T21:40:45.365115'
and p1_0.is_hidden=false
order by
p1_0.vote_count desc
limit 30000,10;
실행 계획
[
{
"id" : 1,
"select_type" : "SIMPLE",
"table" : "p1_0",
"partitions" : null,
"type" : "index",
"possible_keys" : "PRIMARY,fk_post_member1_idx",
"key" : "idx_vote_count",
"key_len" : "8",
"ref" : null,
"rows" : 30010,
"filtered" : 3.33,
"Extra" : "Using where; Backward index scan; Using temporary"
},
{
"id" : 1,
"select_type" : "SIMPLE",
"table" : "w1_0",
"partitions" : null,
"type" : "eq_ref",
"possible_keys" : "PRIMARY",
"key" : "PRIMARY",
"key_len" : "8",
"ref" : "votogether.p1_0.member_id",
"rows" : 1,
"filtered" : 100.00,
"Extra" : null
},
{
"id" : 1,
"select_type" : "SIMPLE",
"table" : "p2_0",
"partitions" : null,
"type" : "eq_ref",
"possible_keys" : "idx_post_id_category_id,fk_post_category_post1_idx,fk_post_category_category1_idx",
"key" : "idx_post_id_category_id",
"key_len" : "16",
"ref" : "votogether.p1_0.id,const",
"rows" : 1,
"filtered" : 100.00,
"Extra" : "Using index; Distinct"
}
]
성능 결과
[Total Time] = [270ms]
실행 계획을 보고있다가 더 개선할 부분이 보였다. 바로 Post 테이블 실행계획에서 filtered가 겨우 3.33%에 그친다는 것이다. 즉, 최종적으로 필요없는 레코드를 96.6%나 더 스캔하고 있는 것이다.
이유가 뭘까. type에 ‘index’ , rows에 ‘30010’ , Extra에 ‘Backward index scan’ 이 적혀있다. 즉, 30001번째부터 10개를 가져와야 하니 30010개의 레코드를 거꾸로 쭉 스캔하는 것이다.
filtered를 최대한 100%에 가깝게 만들어서 더 효율적으로 개선할 수 없을지 고민하면서 Mysql을 공부하고 있는 중에 커버링 인덱스라는 것을 알게 되었다. 내가 딱 원하는 기술이었다.
커버링 인덱스에 대해 자세히 알고 싶으면, 커버링 인덱스 (기본 지식 / WHERE / GROUP BY) - 이동욱 이 글을 참고하면 정말 좋을 것이다.
2. 성능 개선 과정
커버링 인덱스를 적용하기 위해 먼저 해야할 일이 있다. 바로 현재 발생하는 쿼리에서 ‘성능에 영향을 끼치는 where, order by, limit 부분을 따로 추출’ 해서 2개의 쿼리를 활용하는 것이다. 이유는 커버링 인덱스를 사용하려면 하나의 쿼리 안에서 select, where, group by, order by에서 사용되는 모든 컬럼이 인덱스에 있어야하기 때문이다.
이 사실을 인지하고 현재 발생하고 있는 쿼리를 다시 보자. select에 무지막지하게 많은 컬럼들이 있는데, 저 컬럼들을 전부 모아서 하나의 인덱스로 설정할 수는 없는 노릇 아닌가? 배보다 배꼽이 커지는 상황일 것이다.
select
distinct p1_0.id,
p1_0.created_at,
p1_0.is_hidden,
p1_0.content,
p1_0.title,
p1_0.deadline,
p1_0.updated_at,
p1_0.vote_count,
p1_0.member_id,
w1_0.id,
w1_0.alarm_checked_at,
w1_0.birth_year,
w1_0.created_at,
w1_0.gender,
w1_0.nickname,
w1_0.roles,
w1_0.social_id,
w1_0.social_type,
w1_0.updated_at
from
post p1_0
join
member w1_0
on w1_0.id=p1_0.member_id
left join
post_category p2_0
on p1_0.id=p2_0.post_id
where
p2_0.category_id=1
and p1_0.deadline>'2023-11-04T21:40:45.365115'
and p1_0.is_hidden=false
order by
p1_0.vote_count desc
limit 30000,10;
이제 Querydsl의 코드를 개선해서 쿼리를 나누려고 한다. 일단 개선하기 전에 현재 코드를 보자.
인기순 전체 게시글 조회 QueryDsl 코드
@RequiredArgsConstructor
@Repository
public class PostCustomRepositoryImpl implements PostCustomRepository {
private final JPAQueryFactory jpaQueryFactory;
@Override
public List<Post> findPostsWithFilteringAndPaging(
final PostClosingType postClosingType,
final PostSortType postSortType,
final Long categoryId,
final Pageable pageable
) {
return jpaQueryFactory
.selectDistinct(post)
.from(post)
.join(post.writer).fetchJoin()
.leftJoin(post.postCategories, postCategory)
.where(
categoryIdEq(categoryId),
deadlineEq(postClosingType),
post.isHidden.eq(false)
)
.orderBy(orderBy(postSortType))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}
private BooleanExpression categoryIdEq(final Long categoryId) {
return categoryId == null ? null : postCategory.category.id.eq(categoryId);
}
private BooleanExpression deadlineEq(final PostClosingType postClosingType) {
final LocalDateTime now = LocalDateTime.now();
return switch (postClosingType) {
case PROGRESS -> post.postDeadline.deadline.after(now);
case CLOSED -> post.postDeadline.deadline.before(now);
default -> null;
};
}
private OrderSpecifier orderBy(final PostSortType postSortType) {
return switch (postSortType) {
case LATEST -> post.id.desc();
case HOT -> post.voteCount.desc();
default -> OrderByNull.DEFAULT;
};
}
}
findPostsWithFilteringAndPaging() 메서드 내부에서 where, order by, limit에 해당하는 부분을 추출해보자.
인기순 전체 게시글 조회 QueryDsl 코드
@RequiredArgsConstructor
@Repository
public class PostCustomRepositoryImpl implements PostCustomRepository {
private final JPAQueryFactory jpaQueryFactory;
@Override
public List<Post> findPostsWithFilteringAndPaging(
final PostClosingType postClosingType,
final PostSortType postSortType,
final Long categoryId,
final Pageable pageable
) {
List<Long> postIds = jpaQueryFactory
.select(post.id)
.from(post)
.leftJoin(post.postCategories, postCategory)
.where(
categoryIdEq(categoryId),
deadlineEq(postClosingType),
post.isHidden.eq(false)
)
.orderBy(orderBy(postSortType))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
return jpaQueryFactory
.selectDistinct(post)
.from(post)
.join(post.writer).fetchJoin()
.where(post.id.in(postIds))
.orderBy(orderBy(postSortType))
.fetch();
}
}
발생하는 주요 쿼리 2개를 보자. 첫번째 쿼리를 보면 select엔 id만 있는 것을 볼 수 있다. 즉, 이제는 충분히 커버링 인덱스를 첫번째 쿼리에 적용할 수 있다는 의미가 된다.
그렇게 성능에 제일 영향을 미칠 1번 쿼리의 성능을 커버링 인덱스로 최대한 끌어올린다. 그리고 1번 쿼리에서 가져온 10개의 Post id들을 통해, 2번 쿼리에서 member만 join해서 데이터 조회를 완성하는 것이다. 어차피 2번 쿼리는 10개의 데이터만 가지고 작업하기 때문에 속도가 굉장히 빠르다.
발생한 주요 쿼리
-- 1번 쿼리
select
p1.id
from
post p1
left join
post_category p2
on p1.id=p2.post_id
where
p2.category_id=? -- 1번째 인자
and p1_0.deadline>? -- 2번째 인자
and p1.is_hidden=? -- 3번째 인자
order by
p1.vote_count desc
limit ?, ?; -- 4, 5번째 인자
-- 2번 쿼리
select
distinct p1_0.id,
p1_0.created_at,
p1_0.is_hidden,
p1_0.content,
p1_0.title,
p1_0.deadline,
p1_0.updated_at,
p1_0.vote_count,
p1_0.member_id,
w1_0.id,
w1_0.alarm_checked_at,
w1_0.birth_year,
w1_0.created_at,
w1_0.gender,
w1_0.nickname,
w1_0.roles,
w1_0.social_id,
w1_0.social_type,
w1_0.updated_at
from
post p1_0
join
member w1_0
on w1_0.id=p1_0.member_id
where
p1_0.id in (?, ?, ?, ?, ?, ?, ?, ?, ?, ?) -- 여러 Post의 id 인자
order by
p1_0.vote_count desc;
참고로 아까 위쪽에 나왔던 실행계획을 보면 알겠지만, post_category 테이블은 이미 post_id, category_id 로 설정된 인덱스가 존재해서, 이미 커버링 인덱스(Extra : Using index)를 타고 있다.
이제 가장 중요한 1번 쿼리에서 post 테이블의 커버링 인덱스를 설정해보자. 커버링 인덱스를 설정할 땐 컬럼의 순서를 잘 지켜줘야 효율적인 사용이 가능해진다.
결론부터 말하자면, ‘where절의 동등 비교 컬럼’ + ‘order by 또는 group by 의 컬럼’ 은 순서대로 지정해줘야 가장 효율적으로 커버링 인덱스를 타게 된다. 또한 ‘where절의 범위 비교 컬럼’ 은 직접 실험해본 결과, 맨 뒤쪽 순서에 두어야만 Mysql의 옵티마이저가 효율적으로 커버링 인덱스를 타도록 실행 계획을 설계한다는 것이다.
2개의 쿼리문의 실행계획을, 인덱스 컬럼 3개의 순서를 바꿔가면서 테스트 해볼 것이다.
실행계획을 살펴볼, 인기순으로 전체 게시글을 조회하는 쿼리문
where 동등 비교 : is_hidden
order by : vote_count
explain select p1_0.id from post p1_0 left join post_category p2_0 on p1_0.id=p2_0.post_id where p2_0.category_id=1 and p1_0.is_hidden=false order by p1_0.vote_count desc limit 30000, 10;
실행계획을 살펴볼, 인기순으로 마감된 게시글만 조회하는 쿼리문
where 범위 비교 : deadline
where 동등 비교 : is_hidden
order by : vote_count
explain select p1_0.id from post p1_0 left join post_category p2_0 on p1_0.id=p2_0.post_id where p2_0.category_id=1 and p1_0.deadline>'2023-11-03T14:44:57.702977' and p1_0.is_hidden=false order by p1_0.vote_count desc limit 30000, 10;
1. where절의 동등 비교 컬럼 -> order by 또는 group by 컬럼 -> where절의 범위 비교 컬럼
CREATE INDEX idx_is_hidden_vote_count_deadline ON post (is_hidden, vote_count DESC, deadline);
인기순으로 전체 게시글 조회 (where 동등 비교 : is_hidden, order by : vote_count)
실행 계획 (Post 테이블에 대한 부분만) { "id" : 1, "select_type" : "SIMPLE", "table" : "p1_0", "partitions" : null, "type" : "ref", "possible_keys" : "PRIMARY,idx_is_hidden_vote_count_deadline", "key" : "idx_is_hidden_vote_count_deadline", "key_len" : "1", "ref" : "const", "rows" : 49785, "filtered" : 100.00, "Extra" : "Using index" }전체 게시글 조회 쿼리문엔 deadline이 없지만, 앞의 2개의 컬럼(is_hidden, vote_count)이 인덱스에 순서대로 존재하기 때문에 커버링 인덱스를 제대로 효율적으로 타고 있다. (Extra에 Using index밖에 없다)
- filtered 100%라는 극강의 효율을 자랑하고 있다.
인기순으로 마감된 게시글만 조회 (where 범위 비교 : deadline, where 동등 비교 : is_hidden, order by : vote_count)
실행 계획 (Post 테이블에 대한 부분만) { "id" : 1, "select_type" : "SIMPLE", "table" : "p1_0", "partitions" : null, "type" : "ref", "possible_keys" : "PRIMARY,idx_is_hidden_vote_count_deadline", "key" : "idx_is_hidden_vote_count_deadline", "key_len" : "1", "ref" : "const", "rows" : 49785, "filtered" : 33.33, "Extra" : "Using where; Using index" }is_hidden -> vote_count까진 커버링 인덱스로 제대로 필터링 된다.
그리고 그 필터링 된 데이터들 중에서 deadline 범위 비교를 할 때 Mysql 엔진에서 Using where로 다시 필터링 한다는 것을 유추할 수 있다.
- daedline의 필터링 작업에 의해 filtered가 100%가 아닌 33%이지만, Using filesort가 없는 것만으로도 엄청나게 효율적이라 할 수 있다.
2. order by 또는 group by 컬럼 -> where절의 범위 비교 컬럼 -> where절의 동등 비교 컬럼
CREATE INDEX idx_vote_count_deadline_is_hidden ON post (vote_count DESC, deadline, is_hidden);
인기순으로 전체 게시글 조회 (where 동등 비교 : is_hidden, order by : vote_count)
실행 계획 (Post 테이블에 대한 부분만) { "id" : 1, "select_type" : "SIMPLE", "table" : "p1_0", "partitions" : null, "type" : "index", "possible_keys" : "PRIMARY", "key" : "idx_vote_count_deadline_is_hidden", "key_len" : "17", "ref" : null, "rows" : 30010, "filtered" : 10.00, "Extra" : "Using where; Using index" }- Extra의 Using index인 것을 보면 커버링 인덱스를 활용하긴 했다.
- 하지만 위의 1번 상황(type : ref)과 달리, 인덱스 풀 스캔(type : index)을 하고 있다.
- 그리고 Mysql 엔진에서 또 다시 어떤 것이 조건에 부합한 지(Using where) 필터링 하는 모습이다.
- 이는 결국 효율적으로 인덱스 정렬이 안되어서 발생하는 현상이다. (filtered : 10%)
인기순으로 마감된 게시글만 조회 (where 범위 비교 : deadline, where 동등 비교 : is_hidden, order by : vote_count)
실행 계획 (Post 테이블에 대한 부분만) { "id" : 1, "select_type" : "SIMPLE", "table" : "p1_0", "partitions" : null, "type" : "index", "possible_keys" : "PRIMARY", "key" : "idx_vote_count_deadline_is_hidden", "key_len" : "17", "ref" : null, "rows" : 30010, "filtered" : 3.33, "Extra" : "Using where; Using index" }2번의 인기순으로 전체 게시글 조회 상황과 완전 똑같은 상황이다.
- 더해서 filtered는 3.33%로 효율이 훨씬 더 낮은 모습이다.
3. where절의 범위 비교 컬럼 -> where절의 동등 비교 컬럼 -> order by 또는 group by 컬럼
CREATE INDEX idx_deadline_is_hidden_vote_count ON post (deadline, is_hidden, vote_count DESC);
인기순으로 전체 게시글 조회 (where 동등 비교 : is_hidden, order by : vote_count)
실행 계획 (Post 테이블에 대한 부분만) { "id" : 1, "select_type" : "SIMPLE", "table" : "p1_0", "partitions" : null, "type" : "index", "possible_keys" : "PRIMARY", "key" : "idx_vote_count", "key_len" : "8", "ref" : null, "rows" : 30010, "filtered" : 10.00, "Extra" : "Using where; Backward index scan" }- 설정한 인덱스를 사용하지 못할 뿐 아니라, 결국 인덱스를 풀 스캔 하고 있다.
- 커버링 인덱스 조차 아니다. 즉, Clustered Index B-Tree의 리프노드까지 접근한다는 소리이다. (효율 하락)
인기순으로 마감된 게시글만 조회 (where 범위 비교 : deadline, where 동등 비교 : is_hidden, order by : vote_count)
실행 계획 (Post 테이블에 대한 부분만) { "id" : 1, "select_type" : "SIMPLE", "table" : "p1_0", "partitions" : null, "type" : "range", "possible_keys" : "PRIMARY,idx_is_hidden_vote_count_deadline", "key" : "idx_deadline_is_hidden_vote_count", "key_len" : "8", "ref" : null, "rows" : 49785, "filtered" : 10.00, "Extra" : "Using where; Using index; Using filesort" }type : range 인 것을 보면, 인덱스의 첫 컬럼인 deadline을 필터링 할 때를 나타내는 것 같다.
- 문제는 is_hidden, vote_count를 필터링 할 땐, Mysql 엔진에서 Using filesort로 정렬하고 Using where로 필터링 하는 것으로 보인다. (효율 하락)
4. where절의 범위 비교 컬럼 -> order by 또는 group by 컬럼 -> where절의 동등 비교 컬럼
CREATE INDEX idx_deadline_vote_count_is_hidden ON post (deadline, vote_count DESC, is_hidden);
인기순으로 전체 게시글 조회 (where 동등 비교 : is_hidden, order by : vote_count)
실행 계획 (Post 테이블에 대한 부분만) { "id" : 1, "select_type" : "SIMPLE", "table" : "p1_0", "partitions" : null, "type" : "index", "possible_keys" : "PRIMARY", "key" : "idx_vote_count", "key_len" : "8", "ref" : null, "rows" : 30010, "filtered" : 10.00, "Extra" : "Using where; Backward index scan" }- 위 3번의 상황과 동일
인기순으로 마감된 게시글만 조회 (where 범위 비교 : deadline, where 동등 비교 : is_hidden, order by : vote_count)
실행 계획 (Post 테이블에 대한 부분만) { "id" : 1, "select_type" : "SIMPLE", "table" : "p1_0", "partitions" : null, "type" : "range", "possible_keys" : "PRIMARY,idx_is_hidden_vote_count_deadline", "key" : "idx_is_hidden_vote_count_deadline", "key_len" : "8", "ref" : null, "rows" : 49785, "filtered" : 10.00, "Extra" : "Using where; Using index; Using filesort" }- 위 3번 상황과 동일
즉, 커버링 인덱스 설정 시 올바른 컬럼 순서는 where절의 동등 비교 컬럼(is_hidden) -> order by 또는 group by 컬럼(vote_count) -> where절의 범위 비교 컬럼(deadline)순이라는 것을 기억하자.
where a = 1
order by b, c
where a = 1
order by a, b, c
-- Mysql의 옵티마이저가 1번째 쿼리를 2번째 쿼리와 같은 상황으로 쳐주면서 효율적으로 실행 계획을 결정해주기 때문이다.
-- 이렇게 효율적 필터링 처리를 먼저 진행하고 범위 비교를 처리해야 가장 효율적이라는 것을 Mysql의 옵티마이저는 이미 알고 있는 것처럼 보인다.
한 가지 더 중요한 사실은, join에서 쓰이고 있는 Post의 id(PK)는 어차피 인덱스(Non Clustered Key) B-Tree의 리프노드에 이미 존재하므로 인덱스 설정에 포함하지 않아도 된다.
이제 가장 효율적인 순서로 판명된 1번의 컬럼 순서대로 인덱스를 설정하자.
-- 1번 쿼리를 위한 커버링 인덱스 추가
CREATE INDEX idx_is_hidden_vote_count_deadline ON post (is_hidden, vote_count DESC, deadline);
이제 Swagger로 성능 테스트를 진행해보면,
성능 결과
[Total Time] = [80ms]
이전 글에서 반정규화를 통해 성능 개선 후 나왔던 0.27초 보다도 3~4배가 더 빨라진 모습을 볼 수 있다.
이제 부하 테스트를 진행해보자.
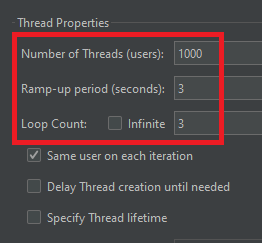
먼저 저번 글에서와 똑같이 3초동안 초당 1000명의 유저가 반복 요청(총 3000번 요청)을 보내도록 설정했다.
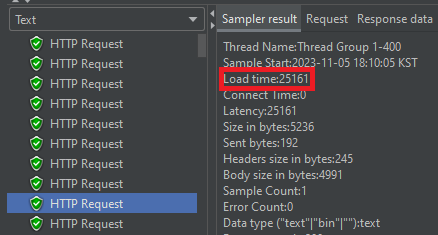
부하 테스트 결과, 저번 글에선 하나의 요청 당 87초가 걸린 반면, 지금은 25초로 줄었다.
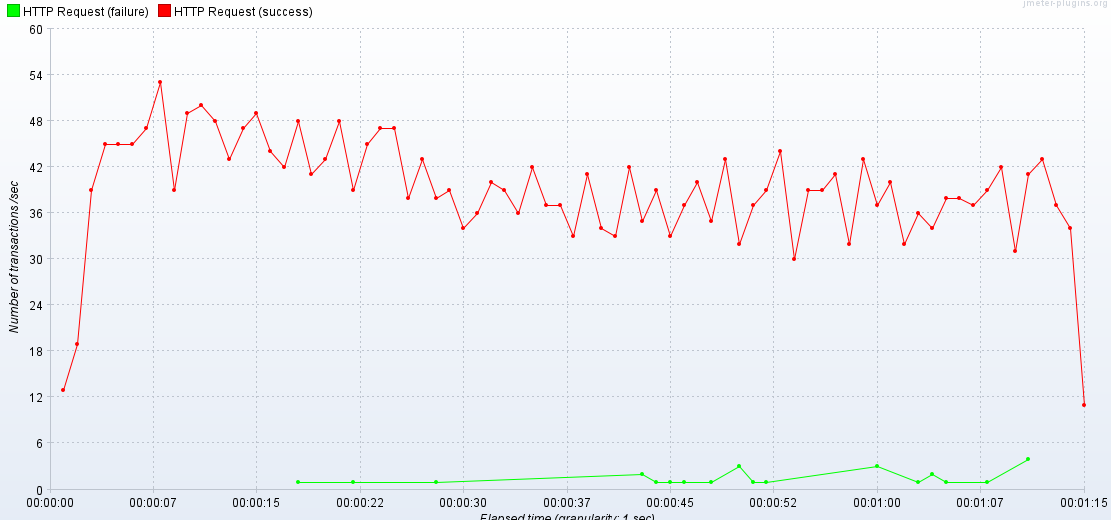
또한 에러 비율은 저번 글에선 6.5%가 나온 반면, 지금은 0.87%로 줄었다.

어플리케이션 성능이 DB에 의해 많이 좌지우지 된다는 것을 깨닫고 난 후 요즘은, Mysql에 대한 공부가 점점 더 재밌어진다.