[Mysql, Querydsl] 반정규화를 통한 조회 성능 개선 (트래픽 부하 테스트)
프로젝트 하는동안 너무 바빠서 이제 다시 올리기 시작
1. 문제 발생
진행했던 프로젝트에서 우리는 대용량 데이터 테스트를 위해 개발 서버에 2000만 건 이상의 데이터를 넣었다.
그리고 ‘인기순 전체 게시글 목록 조회’ 라는 중요한 기능이 있다. 전체의 Post를 Vote(투표)가 많은 순으로 정렬해서, Spring Data JPA의 Pagination을 활용하여 10개씩 가져오는 기능이다.
문제는 개발서버에서 QA를 할 때, 이 조회 기능을 한 번씩 실행할 때마다 8초 이상이 걸린다는 것이다. 우리 팀은 운영서버로 배포하기 전에 항상 개발서버에서 QA 타임을 가지는데, 속도가 너무 느려서 시간이 오래 걸리는 것이다.
해당 기능을 Jmeter를 통해 트래픽 부하 테스트도 진행해보았다. 물론 실제 운영 서버엔 회원수 200명, 게시글 수 700건, 투표 수 7000건 정도라서 부하 테스트는 아직 이르지만, 이처럼 개발 서버에 많은 데이터가 있을 때를 기회로 삼아서 트래픽 부하 테스트를 통한 성능 개선을 경험해보고자 하였다.
먼저 5초동안 초당 30명의 유저가 반복 요청(총 150번 요청)을 보내도록 설정했다.
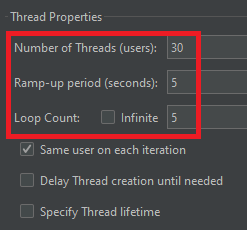
부하 테스트를 해본 결과, 한 번씩 요청 보내면서 테스트 했을 때 8초가 걸린 것과는 달리, 하나의 요청당 48초가 걸리는 모습이다.
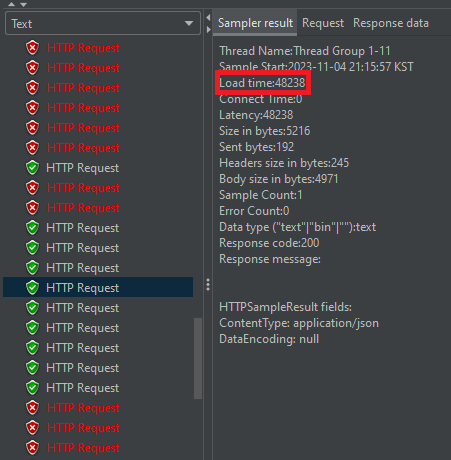
또한 에러 비율이 38%인 모습이다. 현재 상태에선 초당 30건의 요청도 처리하기 힘들다는 뜻이다.

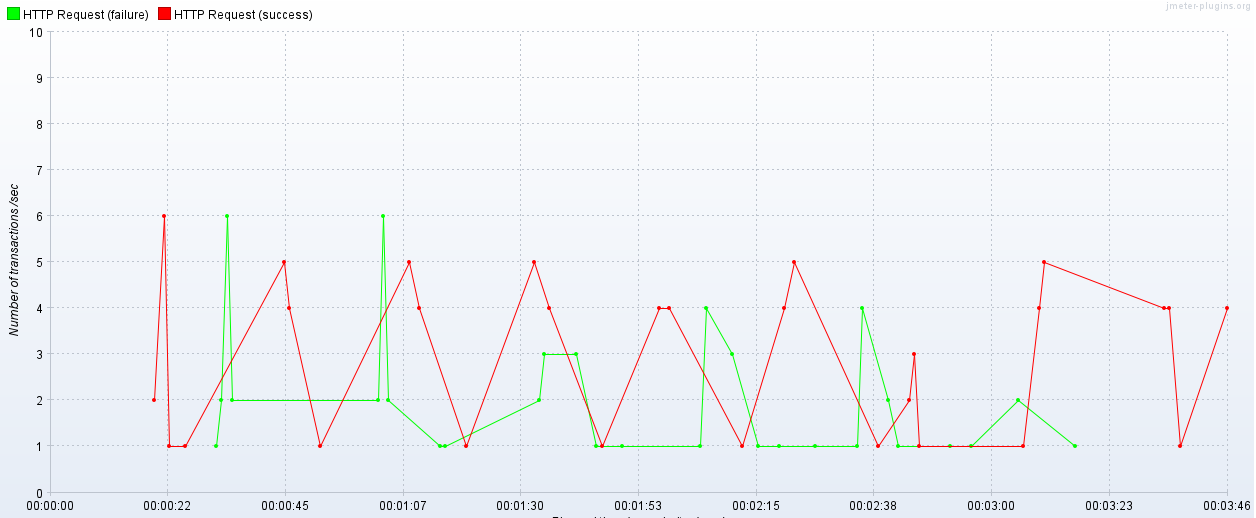
2. 원인 분석
먼저 엔티티 연관관계를 간단히 살펴보면,
- Post -> @OneToMany -> PostOption -> @OneToMany -> Vote
- Post <- @ManyToOne <- PostOption <- @ManyToOne <- Vote
이처럼 Post부터 Vote까지 전부 양방향 매핑관계를 맺어주고 있는 상태이다. 이 관계를 참고하면서 ‘인기순 전체 게시글 목록 조회’ 기능의 실제 코드를 보자. 먼저 Post의 Service 클래스이다.
@RequiredArgsConstructor
@Service
public class PostGuestService {
private static final int BASIC_PAGE_SIZE = 10;
private final PostRepository postRepository;
private final PostCategoryRepository postCategoryRepository;
@Transactional(readOnly = true)
public List<PostResponse> getPosts(
final int page,
final PostClosingType postClosingType,
final PostSortType postSortType,
final Long categoryId
) {
final Pageable pageable = PageRequest.of(page, BASIC_PAGE_SIZE);
final List<Post> posts =
postRepository.findPostsWithFilteringAndPaging(postClosingType, postSortType, categoryId, pageable);
return convertToResponses(posts);
}
... 생략
}
getPosts() 메서드의 파라미터 설명
- page : 이동할 페이지 번호
- postClosingType : 게시글 투표 마감 여부 (전체, 마감, 마감안됨)
- postSortType : 전체 게시글 정렬 기준 (최신순, 인기순)
- categoryId : 카테고리 ID (IT, 고민, 운동, 연애 등등…)
이제 Querydsl이 있는 findPostsWithFilteringAndPaging() 메서드 내부 코드를 살펴보자.
@RequiredArgsConstructor
@Repository
public class PostCustomRepositoryImpl implements PostCustomRepository {
private final JPAQueryFactory jpaQueryFactory;
@Override
public List<Post> findPostsWithFilteringAndPaging(
final PostClosingType postClosingType,
final PostSortType postSortType,
final Long categoryId,
final Pageable pageable
) {
return jpaQueryFactory
.selectDistinct(post)
.from(post)
.join(post.writer).fetchJoin()
.leftJoin(post.postCategories, postCategory)
.where(
categoryIdEq(categoryId),
deadlineEq(postClosingType),
post.isHidden.eq(false)
)
.orderBy(orderBy(postSortType))
.offset(pageable.getOffset())
.limit(pageable.getPageSize())
.fetch();
}
private BooleanExpression categoryIdEq(final Long categoryId) {
return categoryId == null ? null : postCategory.category.id.eq(categoryId);
}
private BooleanExpression deadlineEq(final PostClosingType postClosingType) {
final LocalDateTime now = LocalDateTime.now();
return switch (postClosingType) {
case PROGRESS -> post.postDeadline.deadline.after(now);
case CLOSED -> post.postDeadline.deadline.before(now);
default -> null;
};
}
private OrderSpecifier orderBy(final PostSortType postSortType) {
return switch (postSortType) {
case LATEST -> post.createdAt.desc();
case HOT -> new OrderSpecifier<>(
Order.DESC,
JPAExpressions.select(vote.id.count())
.from(vote)
.where(vote.postOption.id.in(
JPAExpressions.select(postOption.id)
.from(postOption)
.where(postOption.post.id.eq(post.id))
))
);
default -> OrderByNull.DEFAULT;
};
}
}
각 Post의 Vote 개수로 정렬하기 위해 작성한 orderBy() 메서드의 HOT case(인기순) 코드를 보면 압권이다. 10만건이 들어있는 Post를 풀스캔 하는 상황인데, Post 하나를 스캔할 때마다 vote count를 구하기 위해 HOT case의 서브쿼리가 계속 실행되는 사태가 발생한다.
이제 이 기능을 Swagger로 테스트해보자. orderBy() 메서드를 보면 인기순(PostSortType == HOT)이 훨씬 더 성능이 느릴 게 뻔하니 인기순으로 테스트 해보겠다.
현재 개발서버 각 테이블 데이터 개수
- post : 10만 건
- post_option : 20만 건
- vote : 2000만 건
테스트 시, 전달한 인자 값
- page : 3000
- postClosingType : PROGRESS (마감 안된 것)
- postSortType : HOT (인기순)
- categoryId : 1 (신경 안써도 되는 부분)
성능 결과부터 보자.
[Query Count] = [13]
[Total Time] = [7908ms]
쿼리는 총 13개가 발생했고, 시간은 총 8초가 걸렸다. 왜 이렇게 속도가 느린지 분석하기 위해, 발생한 13개의 쿼리 중 성능에 99%의 영향을 끼치고 있는 주요 쿼리 1개를 살펴보자.
== 발생한 주요 쿼리 ==
select
distinct p1_0.id,
(select
count(*)
from
comment c
where
c.post_id = p1_0.id),
p1_0.created_at,
p1_0.is_hidden,
p1_0.content,
p1_0.title,
p1_0.deadline,
p1_0.updated_at,
p1_0.member_id,
w1_0.id,
w1_0.birth_year,
w1_0.created_at,
w1_0.gender,
w1_0.nickname,
w1_0.social_id,
w1_0.social_type,
w1_0.updated_at
from
post p1_0
join
member w1_0
on w1_0.id=p1_0.member_id
left join
post_category p2_0
on p1_0.id=p2_0.post_id
where
p2_0.category_id=1
and p1_0.deadline>'2023-11-04T21:40:45.365115'
and p1_0.is_hidden=false
order by
(select
count(v1_0.id)
from
vote v1_0
where
v1_0.post_option_id in
(select
p4_0.id
from
post_option p4_0
where
p4_0.post_id=p1_0.id)
) desc limit 30000,10;
정렬의 기준이 될 vote의 개수를 구하기 위해 order by에서 중첩 서브쿼리로 vote 개수를 구하는 모습이다. 이 쿼리의 실행계획(explain)을 살펴보자.
[
{
"id" : 1,
"select_type" : "PRIMARY",
"table" : "p1_0",
"partitions" : null,
"type" : "ALL",
"possible_keys" : "PRIMARY,fk_post_member1_idx",
"key" : null,
"key_len" : null,
"ref" : null,
"rows" : 99575,
"filtered" : 3.33,
"Extra" : "Using where; Using temporary; Using filesort"
},
{
"id" : 1,
"select_type" : "PRIMARY",
"table" : "w1_0",
"partitions" : null,
"type" : "eq_ref",
"possible_keys" : "PRIMARY",
"key" : "PRIMARY",
"key_len" : "8",
"ref" : "votogether.p1_0.member_id",
"rows" : 1,
"filtered" : 100.00,
"Extra" : null
},
{
"id" : 1,
"select_type" : "PRIMARY",
"table" : "p2_0",
"partitions" : null,
"type" : "eq_ref",
"possible_keys" : "idx_post_id_category_id,fk_post_category_post1_idx,fk_post_category_category1_idx",
"key" : "idx_post_id_category_id",
"key_len" : "16",
"ref" : "votogether.p1_0.id,const",
"rows" : 1,
"filtered" : 100.00,
"Extra" : "Using index; Distinct"
},
{
"id" : 3,
"select_type" : "DEPENDENT SUBQUERY",
"table" : "p4_0",
"partitions" : null,
"type" : "ref",
"possible_keys" : "PRIMARY,post_id,fk_post_option_post1_idx",
"key" : "fk_post_option_post1_idx",
"key_len" : "8",
"ref" : "votogether.p1_0.id",
"rows" : 1,
"filtered" : 100.00,
"Extra" : "Using index"
},
{
"id" : 3,
"select_type" : "DEPENDENT SUBQUERY",
"table" : "v1_0",
"partitions" : null,
"type" : "ref",
"possible_keys" : "fk_vote_post_option1_idx",
"key" : "fk_vote_post_option1_idx",
"key_len" : "8",
"ref" : "votogether.p4_0.id",
"rows" : 102,
"filtered" : 100.00,
"Extra" : "Using index"
},
{
"id" : 2,
"select_type" : "DEPENDENT SUBQUERY",
"table" : "c",
"partitions" : null,
"type" : "ref",
"possible_keys" : "fk_comment_post1_idx",
"key" : "fk_comment_post1_idx",
"key_len" : "8",
"ref" : "votogether.p1_0.id",
"rows" : 1,
"filtered" : 100.00,
"Extra" : "Using index"
}
]
Post 테이블을 제외한 다른 테이블을 조회하는 쿼리들은 커버링 인덱스를 사용하거나 type이 ref 혹은 eq_ref이기 때문에 꽤나 빠른 축에 속한다.
문제는 Post 테이블을 Full table scan (type : ALL) 을 하고 있다는 것이다. 결국 10만건이 들어있는 Post를 풀스캔 하면서, Post 하나를 스캔할 때마다 vote count를 구하는 서브쿼리가 지속적으로 같이 실행되기 때문에 성능 저하가 심할 수밖에 없다.
실제로 해당 쿼리문을 explain analyze 로도 분석해보면, Post 테이블을 스캔할 때 Vote 테이블을 같이 스캔해야하기 때문에, Post 테이블의 10만 레코드를 스캔하는 작업이 가장 오래 걸리는 것으로 나온다.
"-> Table scan on (cost=35520..35627 rows=8330) (actual time=7269..7283 rows=100000 loops=1)"
3. 문제 해결
따라서 생각해낸 해결책은, ‘인기순으로 조회할 때, vote 테이블을 스캔하게 하지 않는 것’ 이다.
해결 과정
- Post 테이블에 vote_count 컬럼을 새로 추가 (반정규화)
- 투표를 할 때마다 Post 테이블의 vote_count 컬럼을 1씩 증가
- 조회할 때, Post 테이블의 vote_count로 정렬
이러면 조회할 땐 Vote 테이블을 스캔하지 않아도 되어 성능이 훨씬 더 올라가게 된다. 이제 실제로 개선한 코드와 성능 결과를 살펴보자.
먼저 VoteService에서 새롭게 추가된, ‘투표를 할 때마다 Post의 voteCount가 1 증가’하는 로직이다.
@Service
@Transactional
@RequiredArgsConstructor
public class VoteService {
private final VoteRepository voteRepository;
private final PostRepository postRepository;
private final PostOptionRepository postOptionRepository;
private final MemberMetricRepository memberMetricRepository;
public void vote(
final Member member,
final Long postId,
final Long postOptionId
) {
final Post post = postRepository.findByIdForUpdate(postId)
.orElseThrow(() -> new NotFoundException(PostExceptionType.NOT_FOUND));
validateAlreadyVoted(member, post);
final PostOption postOption = postOptionRepository.findByIdForUpdate(postOptionId)
.orElseThrow(() -> new NotFoundException(PostOptionExceptionType.NOT_FOUND));
final MemberMetric memberMetric = memberMetricRepository.findByMemberIdForUpdate(member.getId())
.orElseThrow(() -> new NotFoundException(MemberExceptionType.NOT_FOUND_METRIC));
final int voteCount = voteRepository.countByMember(member);
final Vote vote = post.makeVote(member, postOption);
voteRepository.save(vote);
memberMetric.updateVoteCount(voteCount + 1);
post.increaseVoteCount(); // 여기서 Post의 vote_count 컬럼 값이 1 증가한다.
postOption.increaseVoteCount();
}
...생략
}
Querydsl 코드에서 변경된 부분을 살펴보자.
@RequiredArgsConstructor
@Repository
public class PostCustomRepositoryImpl implements PostCustomRepository {
...생략
private OrderSpecifier orderBy(final PostSortType postSortType) {
return switch (postSortType) {
case LATEST -> post.id.desc();
case HOT -> post.voteCount.desc();
default -> OrderByNull.DEFAULT;
};
}
...생략
}
위에서 개선하기 전의 orderBy() 메서드와 비교해보면, HOT case의 코드가 post의 voteCount로 정렬하는 것으로 아주 간결하게 바뀐 모습을 볼 수 있다. 그리고 Post의 vote_count 컬럼에 인덱스를 걸어준다.
이제 swagger로 다시 ‘인기순 전체 게시글 목록 조회’ 기능을 테스트 해보자.
발생한 주요 쿼리
select
distinct p1_0.id,
p1_0.created_at,
p1_0.is_hidden,
p1_0.content,
p1_0.title,
p1_0.deadline,
p1_0.updated_at,
p1_0.vote_count,
p1_0.member_id,
w1_0.id,
w1_0.alarm_checked_at,
w1_0.birth_year,
w1_0.created_at,
w1_0.gender,
w1_0.nickname,
w1_0.roles,
w1_0.social_id,
w1_0.social_type,
w1_0.updated_at
from
post p1_0
join
member w1_0
on w1_0.id=p1_0.member_id
left join
post_category p2_0
on p1_0.id=p2_0.post_id
where
p2_0.category_id=1
and p1_0.deadline>'2023-11-04T21:40:45.365115'
and p1_0.is_hidden=false
order by
p1_0.vote_count desc -- 개선하기 전에 엄청나게 중첩된 서브쿼리가 발생한 것에 비해서 훨씬 개선된 모습이다.
limit 30000,10;
실행 계획을 보면, Post 테이블을 스캔할 때 새로 생성한 idx_vote_count 인덱스를 제대로 타주는 모습을 볼 수 있다. 덕분에 Using filesort도 일어나지 않는다.
물론 filtered가 3.33% 인 것을 보면 성능을 더 개선할 여지가 있어보인다. 다음 글에서 커버링 인덱스를 통해 성능을 더 개선할 예정이다.
실행 계획
[
{
"id" : 1,
"select_type" : "SIMPLE",
"table" : "p1_0",
"partitions" : null,
"type" : "index",
"possible_keys" : "PRIMARY,fk_post_member1_idx",
"key" : "idx_vote_count",
"key_len" : "8",
"ref" : null,
"rows" : 30010,
"filtered" : 3.33,
"Extra" : "Using where; Backward index scan; Using temporary"
},
{
"id" : 1,
"select_type" : "SIMPLE",
"table" : "w1_0",
"partitions" : null,
"type" : "eq_ref",
"possible_keys" : "PRIMARY",
"key" : "PRIMARY",
"key_len" : "8",
"ref" : "votogether.p1_0.member_id",
"rows" : 1,
"filtered" : 100.00,
"Extra" : null
},
{
"id" : 1,
"select_type" : "SIMPLE",
"table" : "p2_0",
"partitions" : null,
"type" : "eq_ref",
"possible_keys" : "idx_post_id_category_id,fk_post_category_post1_idx,fk_post_category_category1_idx",
"key" : "idx_post_id_category_id",
"key_len" : "16",
"ref" : "votogether.p1_0.id,const",
"rows" : 1,
"filtered" : 100.00,
"Extra" : "Using index; Distinct"
}
]
성능 결과
[Total Time] = [270ms]
8초 -> 0.27초 즉, 29~30배 정도 성능이 개선된 모습을 볼 수 있다. 굉장히 성공적인 성능 개선이라고 생각한다.
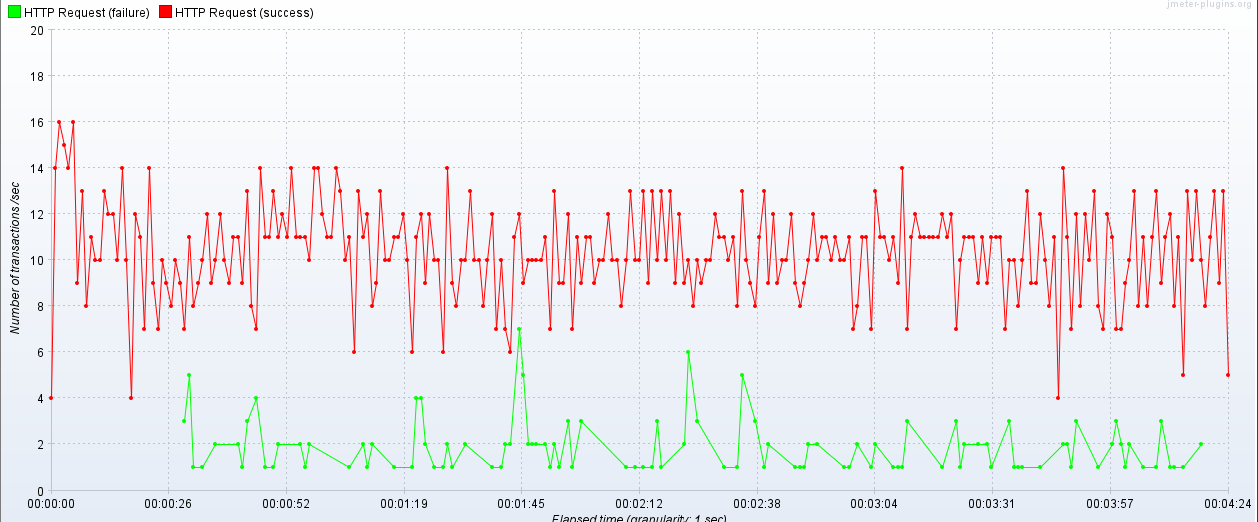
트래픽 부하 테스트도 진행해보았다.
먼저 3초동안 초당 1000명의 유저가 반복 요청(총 3000번 요청)을 보내도록 설정했다.
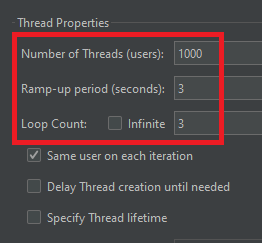
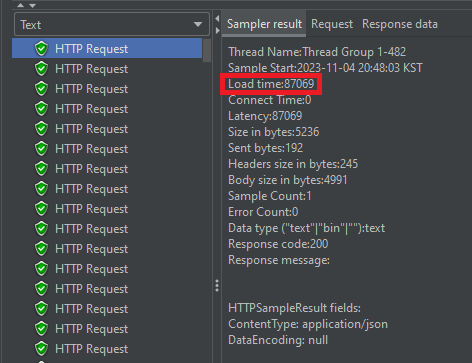
부하 테스트를 해본 결과, 비록 하나의 요청당 86초 정도 걸리게 되었지만, 초당 1000명의 요청에도 에러 비율이 6%대를 유지한다는 점에서 개선하기 전보다 성능이 훨씬 좋아졌다는 것에 의의를 두었다.

물론 이러면 조회 성능이 올라가는 대신 투표하는 insert 기능의 성능이 저하되는 것 아니냐 생각할 수도 있다. 하지만 insert의 성능 변화는 거의 없다고 보면 된다. Post의 voteCount를 1 증가시키는 작업만 추가된 것 뿐이기 때문이다.
실제로 insert 성능(투표 기능)을 swagger로 테스트 해본 결과, 차이가 아예 없었다.
이렇게 조회 성능을 향상시키는 작업을 하면서 항상 느끼는 점은, insert와 select 성능의 trade off는 아주 조금의 손해를 보면서 아주 많은 이익을 볼 수 있는 가성비 작업이라는 것이다.