[Java, Spring] 계층형 아키텍처 vs 헥사고날 아키텍처
뭐가 더 좋아?
- 계층형 아키텍처의 문제점
- 이러한 문제들을 어떻게 해결할 수 있을까?
- 클린 아키텍처 (헥사고날 아키텍처)
- 각 역할마다 클래스를 나누는 기준과 그 이유
- 패키지 구조
- 그럼 앞으로 헥사고날 아키텍처만 사용해야 하는가??
페어 프로그래밍을 하는 도중, 내 페어가 짜는 신기한 구조를 보았다.
서비스를 구현하기에 앞서 유스케이스를 만들고, 또 각 유스케이스를 기능마다 세분화한다.
처음엔 굉장히 비효율적으로 보였다.
그런데 좀 더 고민해보니, 클래스 파일과 패키지를 많이 늘리더라도 유지보수성을 늘리는 것이 더 좋지 않을까 하는 생각이 들었다.
클래스와 등록해야 할 빈이 좀 많이 늘어나는 것은 하드웨어가 많이 발전함에 따라 충분히 커버칠 수 있지 않을까??
이번 기회에 헥사고날 아키텍처에 대해 학습해보고 아주 간단하게나마 정리해보려한다.
계층형 아키텍처의 문제점
주제를 계층형 vs 헥사고날 로 해놓고 일방적으로 계층형을 까는 것 같아서 이상할 순 있지만, 헥사고날이 왜 나왔고 왜 가치가 있는지 따져보려면 계층형의 문제점을 파악할 필요가 있다.
1. 데이터베이스 주도 설계를 유도한다.
ORM(object-relational mapping) 프레임 워크에 의해 DB 중심적이 되기 쉽다. Entity는 일반적으로 영속성 계층에 두는데, Service가 id(식별자)가 포함된 Entity에 접근하게 되면서 도메인 계층과 영속성 계층이 강하게 결합하게 된다. 결국 영속성 코드와 도메인 코드 둘 중 하나만 바꾸는 것이 어려워지는 실정까지 가게 된다. 이는 유연함을 강조하는 계층형 아키텍처의 목표와 반대된다.
2. 지름길을 택하기 쉬워진다.
계층형 아키텍처의 전체적인 주된 규칙은 특정 계층에서는 같은 계층에 있는 컴포넌트나 아래에 있는 계층에만 접근 가능하다는 것이다. 하위 계층(영속성 계층)에서 어떤 상위 계층의 컴포넌트에 접근해야한다면, 가장 쉬운 방법은 그 컴포넌트를 아래계층으로 끌어 내리는 것이다. 결국 상위 계층 컴포넌트들이 지속적으로 끌어내려져서 종국엔 영속성 계층이 비대해질 가능성이 높아진다.
헥사고날에선 각 구현체에 접근 제한자를 걸고 각 Port(Interface)를 통해 사용하게끔 아키텍처를 강제할 수 있다.
3. 테스트하기 어려워진다.
일단 계층형 아키텍처에선 컴포넌트의 크기에 대한 제한이 전혀 없다. 따라서 얼마든지 넓은 컴포넌트를 만들 수 있다. 하나의 관심사에 해당하는 모든 연산 기능이 하나의 컴포넌트에 들어감으로써, 하나의 테스트 클래스에서도 해당 컴포넌트를 보면서 테스트해야할 기능들을 전부 파악해서 예외 케이스까지 테스트 해주려면 난이도가 꽤나 올라갈 것이다.
또한 2번째(지름길을 택하기 쉬워진다.)처럼 접근이 필요한 컴포넌트를 끌어 내리는 것이 아닌, 그냥 계층을 건너뛰고 접근해버리는 경우도 많다. (ex. Controller -> Persistence Layer)
아무리 간단한 조작이라도 결국 비즈니스 로직이 컨트롤러에 퍼지는 것이고, 유스 케이스가 확장된다면 이는 더 심해질 것이다. 이런 경우, 컨트롤러를 테스트함에도 불구하고 서비스뿐만이 아닌 영속성 계층도 Mocking을 해줘야하는 불상사가 생기게 된다.
4. 유스케이스를 숨긴다.
유스케이스 파악이 힘들어진다는 것이다. 이유는 크게 2가지다.
- 유스 케이스(도메인 로직)가 여기저기 퍼져있다.
- 간단한 유스 케이스는 도메인 계층 위치를 고수하지 못하고 여기저기 끌려다닐 수 있다.
- 너무 많은 유스 케이스가 하나의 Service 안에 들어가게 된다.
- 계층형 아키텍처에선 서비스의 너비에 제한을 두고있지 않기 때문이다.
- 나중에 나오지만, 그래서 헥사고날 아키텍처에선 각 유스 케이스를 전부 나눠서 구현하게 된다.
- 이는 각 유스 케이스의 유지보수성을 엄청나게 높이는 결과를 낳게 된다.
- 계층형 아키텍처에선 서비스의 너비에 제한을 두고있지 않기 때문이다.
5. 동시 작업이 어려워진다.
이유는 크게 2가지다.
- 하나의 기능을 나눠서 작업할 수 없다.
- 모든 것은 영속성 계층 위에 만들어지기 때문에, 개발 단계는 영속성 계층 -> 도메인 계층 -> 웹 계층 이 된다.
- 즉, 하나의 기능은 한 개발자가 개발 단계에 맞춰서 개발을 해야하기 때문에, 각 계층을 동시에 개발할 수 없는 상태다.
- 모든 것은 영속성 계층 위에 만들어지기 때문에, 개발 단계는 영속성 계층 -> 도메인 계층 -> 웹 계층 이 된다.
- 여러 유스케이스를 나눠서 작업할 수 없다.
- 계층형 아키텍처는 수많은 유스 케이스 로직이 하나의 서비스에 들어가게 된다.
- 만약 여러 유스 케이스를 나눠서 동시에 작업한다면, 하나의 Service에서 여러명이 작업을 하게 되고, 따라서 merge conflict가 일어나게 될 가능성이 높다.
사실 계층형 아키텍처의 규칙을 처음부터 끝까지 꾸준하게 철저히 지켜준다면 이러한 문제들이 생길 가능성을 낮출 수 있다. 하지만 계층형 아키텍처는 강제성이 많이 부족하기 때문에, 위의 문제들이 발생되도록 꽤나 유도한다. 그런 유도는 마감일이 다가올 수록 훨씬 더 심해지게 될 것이다.
이러한 문제들을 어떻게 해결할 수 있을까?
크게 2가지의 규칙을 바로 세울 수 있어야 한다.
1. 단일 책임 원칙
보통 ‘단일 책임’의 뜻을 ‘오로지 한 가지 일만 하는 것’으로 알고있다. 하지만 ‘단일 책임 원칙’의 의도와는 조금 다르다. ‘책임’이란 단어를 깊게 고민해보며 뜻을 이렇게 바꿔보자.
- ‘특정 컴포넌트가 오로지 한 가지 일만 하는 것’ -> ‘특정 컴포넌트를 변경하는 이유는 오직 하나뿐이다’
따라서 ‘단일 책임 원칙’ -> ‘단일 변경 이유 원칙’ 으로 바꾸는 것도 괜찮지 않을까? 각 컴포넌트의 변경될 이유가 한 가지 뿐이라면, 서로간에 영향을 미칠 일은 극도로 줄어들 것이다.
2. 의존성 역전 원칙
의존 방향을 역전시킬 수 있다는 원칙이다. 즉, ‘웹 계층 -> 도메인 계층 -> 영속성 계층’ 의 일방적인 의존성 방향을 ‘웹 계층 -> 도메인 계층 <- 영속성 계층’ 으로 바꾸는 것이다. 도메인 계층이 다른 계층에 대한 의존성을 다 끊어버려서 도메인이 변경될 이유를 최대한 줄이는 것이 목적이다.
의존성을 역전 시킨 최종적인 모습은 이러하다
웹 계층 -> {UseCase(인터페이스) <- 도메인 -> Port(인터페이스)} <- 영속성 계층
이러한 규칙을 세운 아키텍처가 바로 클린 아키텍처 혹은 헥사고날 아키텍처라고 한다.
클린 아키텍처 (헥사고날 아키텍처)
‘클린 아키텍처’ 는 ‘밥 아저씨(로버트 마틴)’ 가 정립한 아키텍처로써, 계층형 아키텍처의 문제를 위의 2가지 규칙을 세우는 것과 같은 과정으로 해결한 비교적 추상적인 아키텍처라고 한다. ‘헥사고날 아키텍처(육각형 아키텍처)’ 는 ‘알리스테어 콕번’ 이 만든 용어로써, 클린 아키텍처의 원칙들을 더 구체적으로 만든 아키텍처라고 보면 된다.
먼저 클린 아키텍처의 의존성을 살펴보자.
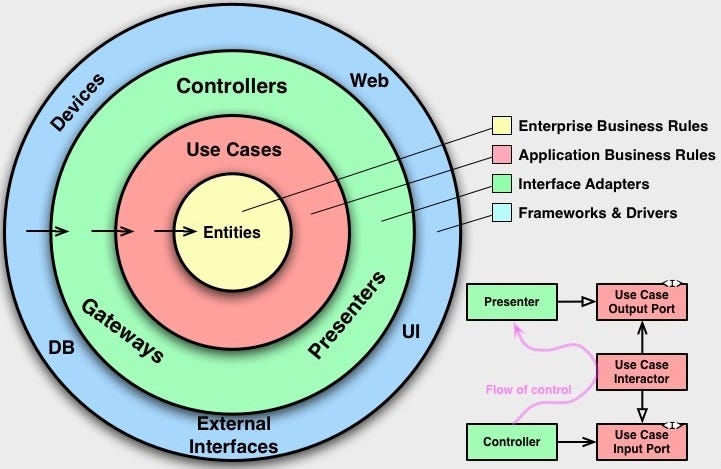
계층형 아키텍처와 가장 큰 차이점은 ‘의존성의 방향’ 이다. 계층형 아키텍처는 웹 계층에서 영속성 계층까지 의존성이 단방향으로 흘러가는 것이라면, 클린 아키텍처는 의존성이 웹 계층과 영속성 계층인 바깥 쪽에서 도메인 계층인 안 쪽으로 흘러간다.
이제 이 클린 아키텍처를 좀 더 구체화한 헥사고날 아키텍처를 살펴보자.
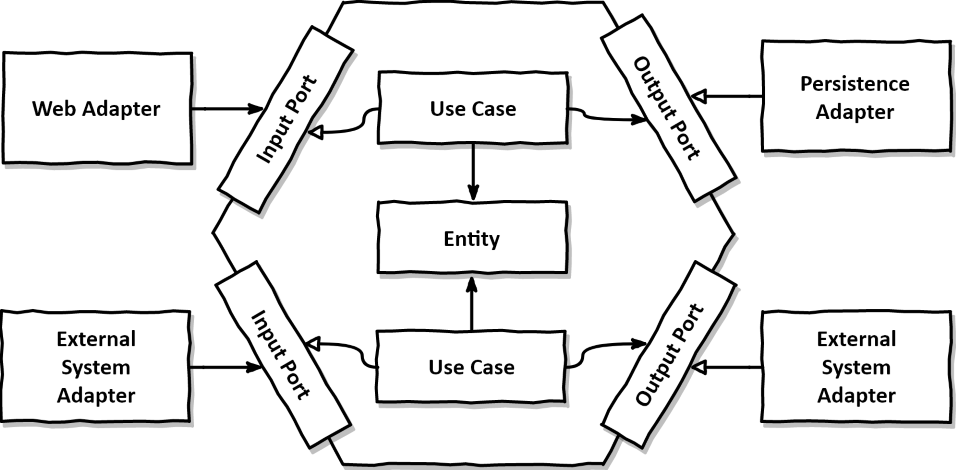
각 포트(인터페이스)가 도메인을 육각형 형태로 감싸서 보호하고 있는 모습이다. 헥사고날(육각형)이란 이름이 붙은 이유는 이 그림에서 볼 수 있듯이 코어가 육각형이라서 그렇다고 한다. (진짜다…)
먼저 각 용어들을 하나씩 살펴보자.
1. Use Case (OOOService - class)
Service 계층에 속하며, Input Port 인터페이스를 구현한 Service라 볼 수 있다. Use Case는 각 비즈니스 로직(각 기능)을 갖고 있다. 그래서 당연히 비즈니스 규칙을 검증한다.
여기서 중요한 것은 입력 유효성 검증을 하지 않는다는 것이다. Use Case는 오직 비즈니스 로직에만 집중하기 위함이다.
그렇다고 Web Adapter에 모든 입력 유효성 검증을 맡기기엔 검증의 신뢰도가 낮아질 수 있다. 정말로 Web Adapter를 전적으로 신뢰하며 입력 값을 사용할 수 있을까? 또한 여러 Web Adapter에서 해당 Use Case를 호출할 수도 있는데, 해당 Use Case를 호출하는 각 Web Adapter에서 유효성 검증을 해주어야 한다. 사람인 이상 그 과정에서 까먹거나 실수를 할 가능성은 언제든지 있다.
때문에 Service로 전달할 ‘입력 모델 (AddLineRequest)’ 을 두는 것이 좋다. 그 입력 모델을 통해 입력 유효성 검증을 진행해 줄 수 있다. 즉 Web Adapter에서 Http 요청 값을 한 번 더 Service의 입력 모델로 매핑한 뒤 서비스로 전달하는 것이다.
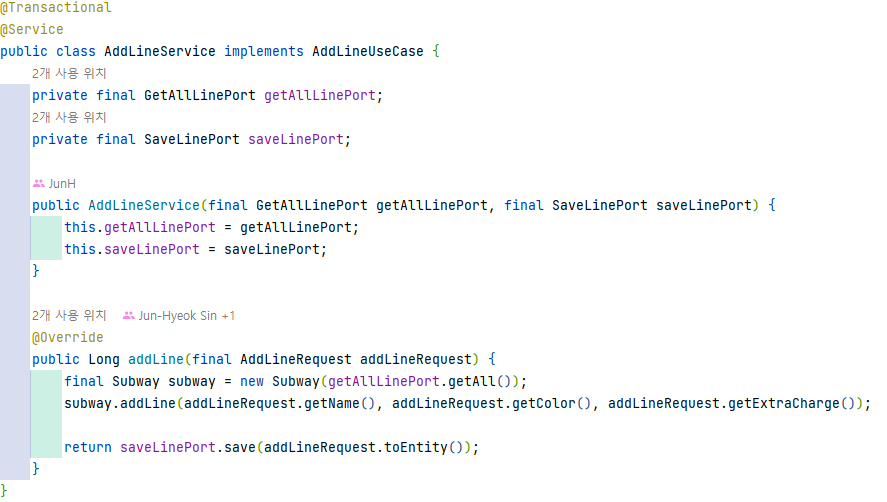
2. Input Port (OOOUseCase - interface)
Service 계층에 속하며, Web Adapter가 코어에 진입할 때의 진입점이 되는 인터페이스이다. Service가 구현하는 인터페이스라 보면 된다.
여기서 Web Adapter와 코어 사이에 굳이 인터페이스를 두어 의존성 역전을 시키는 이유가 납득되지 않을 수 있다. 2가지 이유가 있다.
- 새로운 개발자가 진입점을 식별하기 더 수월해진다.
- Input Port가 없다면 어떤 서비스 메서드를 호출해야할 지 알아내기 위해 내부 동작을 알아야 하지만, Input Port처럼 진입점을 명세해놓는다면 새로운 개발자가 코드의 의도를 파악하기 쉬워진다.
- 아키텍처를 강제하기 쉽다.
- 코어(Service)를 package-private으로 설정하면 WebAdapter에선 Input Port를 통해 코어에 접근하게 될 것이다.

3. Web Adapter (OOOController - class)
Web 계층에 속하며, 컨트롤러라 볼 수 있다. Web Adapter라는 이름에 맞게 HTTP 요청을 자바 객체로 매핑하고, 유스케이스의 반환 값을 HTTP로 매핑해서 응답을 반환하는 역할을 갖고 있다.
어떤 도메인 로직도 갖고있지 않으면서 HTTP와 자바 객체의 매핑에 초점을 맞추는 Adapter 역할에 초점을 맞춰야 한다.
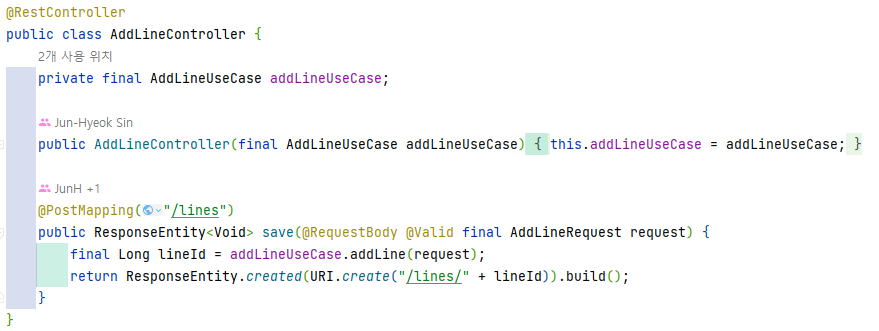
4. Output Port (OOOPort - inerface)
Service 계층에 속하며, Persistence Adapter가 구현하는 인터페이스이다. Domain과 Persistence간의 의존성 역전을 통해 의존성의 방향을 바꿀 때 튀어나온 인터페이스이다. Service는 Output Port를 호출하여 Persistence Adapter와 데이터를 주고 받는다.
Output Port는 좀 특이한 포지션을 갖는다. 원칙적으론 Service 계층이 맞으나, ‘Service 계층과 Persistence 계층 사이의 간접 계층’ 으로 볼 수도 있다.
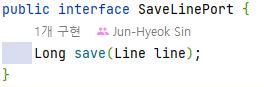
5. Persistence Adapter (OOOAdapter - class)
이 또한 이름처럼 Adapter이기 때문에 매핑의 역할을 갖는다. 어떤 것을?? 도메인 데이터(domain Entity or 특정 값)와 데이터 베이스 포맷(Persistence Entity)이다.

각 역할마다 클래스를 나누는 기준과 그 이유
헥사고날의 주된 특징 중 하나가, 하나의 기능마다 클래스를 전부 나누어주는 것이다. 각 컴포넌트는 각 관심사마다 하나씩만 둘 필요가 전혀 없다. 가능한 한 단일 책임 원칙(특정 컴포넌트를 변경하는 이유는 오직 하나) 에 기반해서, 각 요청을 전부 나누어주는 것이 좋다.
Web Adapter, Input Port, Use Case, Output Port, Persistence Adapter 전부 얼마든지 나누어줄 수 있다.
그 이유는 몇 가지가 있다.
- 가독성이 훨씬 더 뛰어나다
- 한 클래스에 메서드가 많은 것보다, 클래스가 많은 것이 훨씬 가독성이 좋다.
- 클래스에 몇 만줄의 코드가 들어있다면 그보다 파악하기 어려운 유형의 코드는 없을 것이다.
- 클래스가 많아진다고 해도, 요즘의 하드웨어 성능상으론 아무런 문제가 없을 것으로 예상된다.
- 테스트하기가 수월해진다.
- 테스트 코드도 Prod 코드가 어떻게 분리되는지에 따라 같이 분리되기에, 이는 당연하다.
- 또한 테스트를 작성할 때도, 테스트 할 기능을 파악하기 수월해진다.
- 동시 작업이 수월해진다.
- 각 기능들은 전부 클래스로 분리되어있고, 따라서 병합 충돌이 일어날 일이 없다.
- 불필요한 의존성을 제거할 수 있다.
- 단일 컴포넌트는 한 관심사의 모든 연산이 들어있는 ‘넓은 컴포넌트’ 가 된다.
- 넓은 컴포넌트에 대한 의존은 곧, 불필요한 기능들에 대한 의존성도 같이 생겼다는 의미이다.
- 불필요한 데이터 이동을 방지함으로써 코드 파악이 용이해진다.
- 한 관심사의 모든 연산을 단일 컴포넌트에 전부 넣는다면, 여러 기능이 하나의 DTO를 사용하게 될 가능성이 높고, 그 DTO의 크기는 커지게 된다.
- 그러면 어떤 기능은 해당 DTO에서 필요하지도 않은 데이터엔 null을 설정하면서 데이터를 전달하게 된다.
- 각 컴포넌트를 나누면서 그에 맞는 각 입출력 DTO를 따로 만들어주는 것이 그래서 필요하다.
내 개인적으로 Persistence Adapter를 제외한 나머지는 전부 하나의 기능마다 전부 나누어주고, Persistence Adapter는 보통 ‘하나의 바운디드 컨텍스트당’ 즉, 영속성 연산이 필요한 도메인 클래스 하나당 하나의 Persistence Adapter를 구현한다.
물론 Persistence Adapter도 하나의 Output Port씩만 구현하면서 기능마다 전부 나누어줄 수 있다.
하지만 Persistence Adapter가 하나의 관심사에 해당하는 여러 Output Port를 구현하고, 각 Use Case에선 필요한 기능에 따라 Output Port를 골라서 호출만 해주면 되기 때문에, Use Case 입장에서도 어떤 것을 호출해야할 지 파악하는 데에 지장이 별로 없을 것으로 여겼기 때문이다.
또한 도메인 데이터와 데이터 베이스 포맷간의 매핑 기능은 여러 UseCase에 호출된다 하더라도 재활용되는 경우가 많기 때문에, Use Case와 같이 새로운 기능이 추가되는 일이 확연히 적었다.
패키지 구조
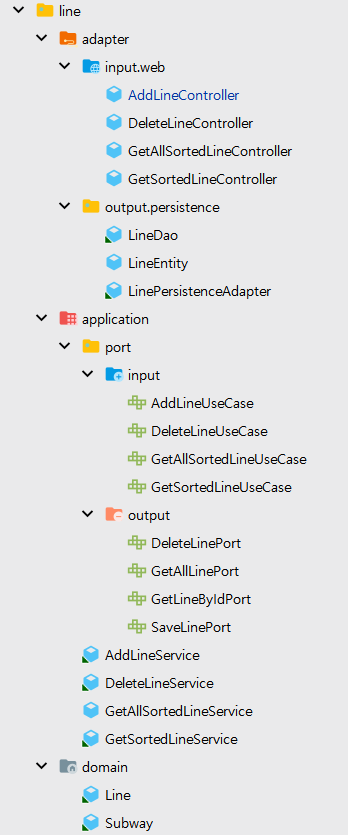
- 관심사별로 크게 패키지를 나눈다.
- adapter(Adapter)와 application(Service) 패키지로 나눈다.
- adapter 패키지는 다시 input과 output으로 나누어서 Web Adapter와 Persistence를 분리한다.
- application 패키지는 Use Case(Service)와 port 를 분리해주고, port 안에서 input과 output을 다시 나눈다.
패키지가 너무 쓸데없이 많은 것처럼 보일 수 있지만, 우린 착각하면 안된다.
우리가 추구해야 할 것은 물건이 별로 없으면서 깔끔하고 잘 정돈된 방이 아니라, 물건이 엄청나게 많으면서도 어떻게든 수납공간을 확보해서 그 물건들을 전부 집어 넣어둔 방이다.
프로그램의 규모가 커지면 커질수록 이러한 장점은 극대화 될 것이다.
그럼 앞으로 헥사고날 아키텍처만 사용해야 하는가??
결론부터 말하자면 ‘상황마다 다르다’ 이다. 이쯤되면 상황마다 다르다는 말은 개발자 종특인 것 같다.
헥사고날이 내세우는 가장 중요한 가치는 외부의 영향을 받지 않고 도메인 코드를 얼마든지 리팩토링 할 수 있다는 것이다. 이는 DDD(도메인 주도 개발)과 밀접한 연관이 있으며, DDD의 조력자라고까지 말한다고 한다. 즉, 도메인이 중요한 애플리케이션이라면 헥사고날 아키텍처가 많은 도움을 줄 것이다. 또한 프로젝트의 규모가 크면 클수록 계층형 아키텍쳐보다 훨씬 더 이점이 클 것이다.
한편으론 시간 제한이 타이트하게 걸려있는 상황에선 경험이 우선될 수 있다. 보통 더 익숙한 아키텍처는 계층형 아키텍처이다. 습관은 무의식적으로 행동으로 옮겨주면서 다른 생각으로 나갈 수 있도록 도와준다. 또한 익숙하기에 그 무엇보다 편안하다. 도메인이 충분히 중요하지 않거나 시간이 촉박하다면 굳이 새로운 아키텍처를 적용할 필요가 있을까??