[MySQL] 페이징 성능 개선 여정 1편 - 잘못된 성능 개선 바로잡기
공부하자
저번 우테코 프로젝트(Votogether)에선 쿼리 분석을 하고 반정규화와 커버링 인덱스를 적용하여 조회 성능을 개선했다.
그런데 이번 DND 프로젝트(따봉도치)에선 반정규화와 커버링 인덱스를 적용하여 성능 개선을 시도했을 때,
원하는 만큼 성능이 개선되지 못했다.
그 이유를 찾으려 MySql을 더 학습하고 원인을 찾아서 결국 0.001초까지 개선했다.
또한 동기화 처리 방식에서도 이전 우테코 프로젝트에서 적용한 방식엔 문제가 있다는 것을 깨닫고 보완하였다.
그 과정을 적어보려 한다.
1. 문제 발단 - 충분치 않은 성능 개선
저번 우테코 플젝이 끝난 뒤에 ‘반정규화’와 ‘커버링 인덱스’를 통한 성능 개선 과정을 글로 작성한 적이 있다.
[Mysql, Querydsl] 반정규화를 통한 조회 성능 개선
[Mysql, Querydsl] 커버링 인덱스와 쿼리 추출을 통한 조회 성능 개선
이때 개발 서버에서 2천만건의 더미 데이터를 넣고, 8초 이상 걸렸던 조회 기능을 0.08초까지 개선한 것으로 기억한다.
이 경험을 살려서 이번 DND 프로젝트에서도 2천만건의 csv 파일 더미 데이터를 파이썬으로 생성한 후, 조회 성능을 개선하기 위해 반정규화와 커버링 인덱스를 적용하여 성능을 개선했다. 그리고 쿼리를 직접 실행헤보며 테스트를 했는데…
10 row(s) returned 9.047 sec / 0.000 sec
당연히 0.1초 이내로 개선될 줄 알았는데 9초가 찍혔다. 물론 반정규화만 해놓고 커버링 인덱스조차 활용하지 않는다면 30초 이상이 걸리면서 아예 조회가 실패하게 된다.
Error Code: 2013. Lost connection to MySQL server during query 30.015 sec
왜 저번과는 다르게 전체적으로 조회 성능이 훨씬 느린지, 그리고 충분하게 성능 개선이 이루어지지 않았는지 원인을 분석해보자.
2. 원인 분석 - 잘못된 성능 테스트 (이전 프로젝트)
먼저 이전 프로젝트에서 성능 테스트 할 때, 주요 DB 테이블들의 데이터 개수와 연관관계 상황을 간단히 살펴보자.
- 더미데이터 개수
- Member : 300건
- Post : 10만건 (FK : member_id)
- PostOption : 20만건 (FK : post_id)
- Vote : 2000만건 (FK : post_option_id, member_id)
그리고 성능을 개선해야 할 조회 쿼리문을 살펴보자. 일단 offset을 30000으로 설정한 모습이 보이고, order by 구문에서 2단계의 서브쿼리를 타면서 레코드 2천만건의 Vote 테이블에 접근하고 있다.
select
distinct p1_0.id,
(select
count(*)
from
comment c
where
c.post_id = p1_0.id),
p1_0.created_at,
p1_0.is_hidden,
p1_0.content,
p1_0.title,
p1_0.deadline,
p1_0.updated_at,
p1_0.member_id,
w1_0.id,
w1_0.birth_year,
w1_0.created_at,
w1_0.gender,
w1_0.nickname,
w1_0.social_id,
w1_0.social_type,
w1_0.updated_at
from
post p1_0
join
member w1_0
on w1_0.id=p1_0.member_id
left join
post_category p2_0
on p1_0.id=p2_0.post_id
where
p2_0.category_id=1
and p1_0.is_hidden=false
order by
(select
count(v1_0.id)
from
vote v1_0
where
v1_0.post_option_id in
(select
p4_0.id
from
post_option p4_0
where
p4_0.post_id=p1_0.id)
) desc limit 30000,10;
저 order by 구문을 개선하기 위해 진행한 반정규화 방식이다.
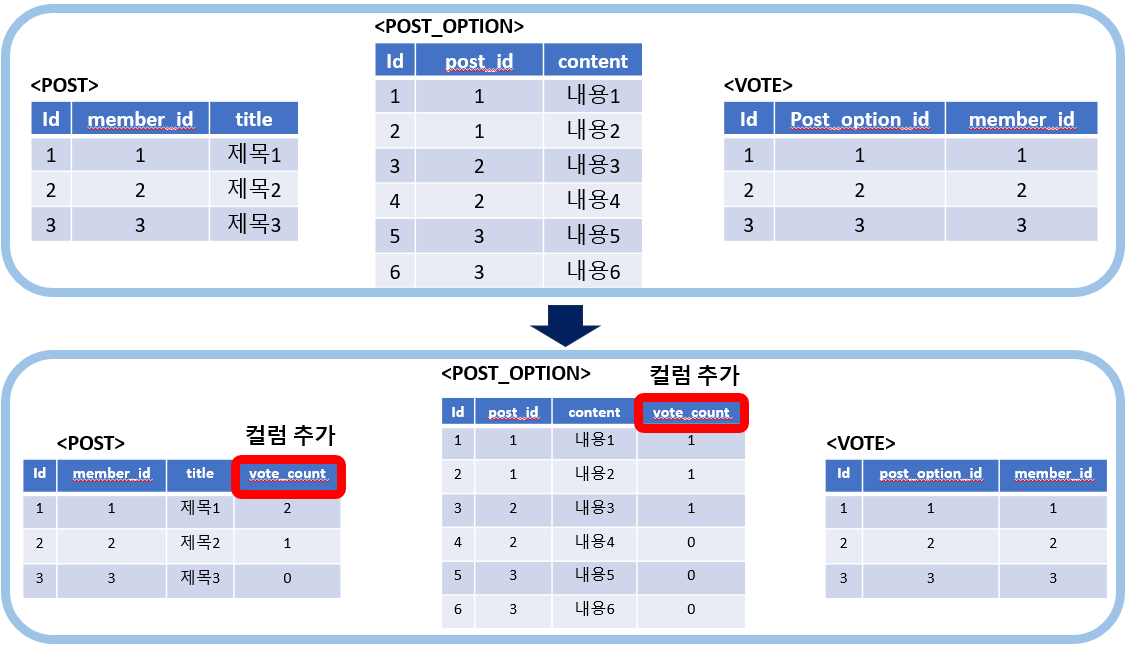
실제로 8초에서 0.27초까지 줄어들 정도로 당연히 성능이 많이 개선되었을 것이다. 반정규화를 통해 정렬의 기준이 되는 vote_count에 인덱스를 걸 수 있게 되었고, 더이상 2천만건의 데이터를 가진 Vote 테이블을 뒤적거리지 않아도 되니까.
그리고 이렇게 개선한 후 vote_count에 인덱스를 걸고 수정한 쿼리의 모습을 살펴보면,
select
distinct p1_0.id,
p1_0.created_at,
p1_0.is_hidden,
p1_0.content,
p1_0.title,
p1_0.deadline,
p1_0.updated_at,
p1_0.vote_count,
p1_0.member_id,
w1_0.id,
w1_0.alarm_checked_at,
w1_0.birth_year,
w1_0.created_at,
w1_0.gender,
w1_0.nickname,
w1_0.roles,
w1_0.social_id,
w1_0.social_type,
w1_0.updated_at
from
post p1_0
join
member w1_0
on w1_0.id=p1_0.member_id
left join
post_category p2_0
on p1_0.id=p2_0.post_id
where
p2_0.category_id=1
and p1_0.is_hidden=false
order by
p1_0.vote_count desc -- 개선하기 전에 엄청나게 중첩된 서브쿼리가 발생한 것에 비해서 훨씬 개선된 모습이다.
limit 30000,10;
아직 커버링 인덱스는 적용하기 전이다.
문제는 여기서부터 이미 시작되었다.
위에서 이미 한 번 언급했듯 반정규화를 통해 성능을 개선한 주요 쿼리만 놓고 보면, 더이상 2천만 레코드인 Vote 테이블과 전혀 상관없는 쿼리문이 되었다. 즉, 이 쿼리문은 이제 2천만건의 데이터로 성능 테스트를 하는게 아니게 되었다는 점이다.
이제 10만건의 Post 테이블에서 offset을 30000으로만 두고 성능을 테스트하니 1초를 넘길리가 없다. ‘아, 이 정도면 웬만한 대용량 데이터 조회 성능은 전부 개선할 수 있는거구나’ 라는 엄청난 착각에 빠지게 되었다.
이후에 커버링 인덱스를 적용하고 0.27 -> 0.08초까지 성능이 나오게 되었다. 여전히 Post 테이블의 데이터는 10만건이며 offset은 3만건이다.
그리고 이번 DND 프로젝트로 넘어와서, Card 테이블에 2천만건의 더미 데이터를 넣고 반정규화와 커버링 인덱스를 적용하여 조회 성능을 해나갔다. 성능을 개선하기 전엔 아예 30초가 넘어가면서 에러가 떴다.
성능 개선을 한 주요 쿼리문을 간단히 살펴보자.
select /*+ INDEX(c1_0 idx_comment_count) */
c1_0.id
from
CARD c1_0
order by
c1_0.comment_count desc
limit 19990000, 10;
저번 프로젝트와 이번 프로젝트의 상황 중 가장 큰 차이점은 from절에 있는 테이블 즉, ‘해당 쿼리문의 주체가 되는 테이블’의 더미 데이터 개수와 Offset 값이다. Card 테이블엔 2천만건의 데이터가 있고 Offset도 1999만으로 설정되어있으니 이제야 제대로 성능 테스트를 진행한 셈이다.
결과는 아까 위에서 언급했듯 ‘9초’ 라는 처참한 성적이 나왔다. 아무리 커버링 인덱스여서 클러스터 인덱스까지 가지 않는다고 해도 1900만개가 넘는 id를 읽는데 당연히 느릴 수밖에…
3. 결론 및 정리 - 학습 부족
굉장히 부끄럽다. 원인은 결국 MySQL의 쿼리문 실행 순서와 Offset에 대한 나의 학습 부족때문이다.
offset은 설정한 값만큼 무조건 데이터를 전부다 읽어버리는 특징이 있다. 내부적으로 쿼리 실행 순서가 select가 먼저 실행되고 마지막에 offset이 실행되기 때문이다.
만약 이러한 쿼리문이 있다고 가정해보자. select 구문에 id가 아닌 전체(*)를 읽어 오도록 했다.
select /*+ INDEX(c1_0 idx_comment_count) */
*
from
CARD c1_0
order by
c1_0.comment_count desc
limit 19990000, 10;
MySQL은 내부적으로 select 구문에서 설정한 컬럼들을 먼저 적용하고 offset 값만큼 레코드(모든 컬럼)를 하나하나 읽으면서 센다. 즉, 조회 결과는 10건만 나오지만 내부적으로 MySQL이 읽는 레코드 실제 개수는 1999만개라는 것이다.
만약 커버링 인덱스 적용을 위해 select 구문에서 id만 조회하게 하면 레코드 하나를 읽을 때마다 id만 읽으면 되니 굉장히 빨라지긴 한다. 하지만 그래도 1900만개가 넘으니 여전히 느릴 수밖에 없다.
왜 Offset은 설정한 값만큼 다 읽어야 하는거야? 인덱스를 통해 어떤 식별자(ex. id)가 offset 값(1999만)인 레코드를 바로 찾아가면 안되는거야?
Offset은 몇 번째인지 나타내는 값이다. 만약 중간 레코드가 하나라도 삭제될 가능성이 있다면, 과연 1999만 값을 가진 id는 1999만번째 레코드라는 것을 보장할 수 있는가?
없다.
그럼 다음 글에서 어떻게 30초 -> 9초로 개선한 성능을 0.001초 이하로 나오도록 개선할 수 있었는지 그 과정을 정리해보려 한다.